



分布式搜索引擎 Elasticsearch
ES 核心术语
- 索引 index ---------------------------------------表
- 类型 type -----------------------------------------表逻辑类型
- 文档 document -----------------------------------行
- 字段 fields ----------------------------------------列
- 映射 mapping ------------------------------------表结构定义
- 近实时 NRT ---------------------------------------Near real time
- 节点 node ----------------------------------------每一个服务器
- shard replica ------------------------------------数据分片和备份
ES集群架构原理
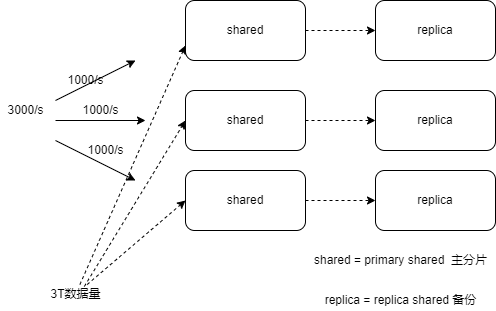
倒排索引
Elasticsearch 的核心配置文件
cd config
// 核心配置文件
ll
elasticsearch.yml
vim elasticsearch.yml
cluster.name------集群名称
node.name-------节点名称
path.data-------数据存储位置
path.logs-------日志存储位置
network.host------本机地址 0.0.0.0
http.port------对外的http端口号
cluster.initial_master_nodes:[""]---------------设置初始的master节点 填node.name
vim jvm.options
-Xms
-Xmx
// 实体机搭建es 不允许root用户启动
useradd esuser
chown -R esuser
一些命令
1. 创建索引
PUT index_temp
{
"settings": {
"index": {
"number_of_shards": "3",
"number_of_replicas": "0"
}
}
}
2. 查看es健康
GET _cluster/health
3. 获取索引信息
GET index_temp
4. 创建索引的同时创建结构
PUT index_mapping
{
"mappings": {
"properties": {
"realname" : {
"type": "text",
"index": true
},
"username" : {
"type": "keyword",
"index": false
}
}
}
}
5. 分词分析
GET index_mapping/_analyze
{
"field": "realname",
"text": "guank is very good"
}
--------------------------
分词响应格式
{
"tokens" : [
{
"token" : "guank",
"start_offset" : 0,
"end_offset" : 5,
"type" : "<ALPHANUM>",
"position" : 0
},
{
"token" : "is",
"start_offset" : 6,
"end_offset" : 8,
"type" : "<ALPHANUM>",
"position" : 1
},
{
"token" : "very",
"start_offset" : 9,
"end_offset" : 13,
"type" : "<ALPHANUM>",
"position" : 2
},
{
"token" : "good",
"start_offset" : 14,
"end_offset" : 18,
"type" : "<ALPHANUM>",
"position" : 3
}
]
}
一旦索引中的属性的数据结构被定义好就不允许修改
6. 为已存在的索引添加 mapping 映射
POST index_mapping/_mapping
{
"properties": {
"id" : {
"type": "long"
},
"age" : {
"type": "integer"
}
}
}
文档的基本操作
1. 在索引下创建一个文档
POST my_doc/_doc/1
{
"id": 1001,
"name" : "guank",
"desc": "guank is very good",
"ceate_date":"2022-09-08"
}
2. 删除文档
DELETE my_doc/_doc/1
3. 修改文档
POST my_doc/_update/2
{
"doc": {
"name" : "guank02"
}
}
4. 根据 _id 查询
GET my_doc/_doc/2
------------------------
返回参数
{
"_index" : "my_doc",
"_type" : "_doc",
"_id" : "2",
"_version" : 3,
"_seq_no" : 4,
"_primary_term" : 1,
"found" : true,
"_source" : {
"id" : 1002,
"name" : "guank02",
"desc" : "guank is very good",
"ceate_date" : "2022-09-08"
}
}
5. 查询索引下所有数据
GET my_doc/_search
------------------------
返回参数
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "my_doc",
"_type" : "_doc",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"id" : 1002,
"name" : "guank02",
"desc" : "guank is very good",
"ceate_date" : "2022-09-08"
}
}
]
}
}
6. 定制返回结果集中包含的属性
GET my_doc/_doc/2?_source=id,name
--------------------------
返回参数
{
"_index" : "my_doc",
"_type" : "_doc",
"_id" : "2",
"_version" : 3,
"_seq_no" : 4,
"_primary_term" : 1,
"found" : true,
"_source" : {
"name" : "guank02",
"id" : 1002
}
}
文档乐观锁控制
// 在更新的时候使用 if_seq_no if_primary_term 通过乐观锁控制
POST my_doc/_doc/1002?if_seq_no=5&if_primary_term=1
{
"doc" : {
"name" : "guank04"
}
}
分词器
POST _analyze
{
"analyzer": "standard",
"text": "i study in guank.com"
}
// es 内置的分词器
simple
standard
whitespace
keyword
stop
使用 ik 分词器
使用自定义的词典
cd elasticsearch/plugins/ik/config
// 文件名
IKAnalyzer.cfg.xml
DSL语法入门
1.根据条件查询
QueryString 方式
GET my_doc/_search?q=desc:guank&q=name:guank
JSON 方式
POST my_doc/_search
{
"query":{
"match":{
"desc":"guank"
}
}
}
POST my_doc/_search
{
"query": {
"exists": {
"field": "name"
}
}
}
查询所有
POST my_doc/_search
{
"query": {
"match_all": {}
}
}
// 查询
POST my_doc/_search
{
"query": {
"match_all": {}
},
"_source": [
"id",
"name",
"desc"
]
, "from": 0
, "size": 20
}
POST my_doc/_search
{
"query": {
//"term": {
// "desc":"guank" term关键字作用搜索条件不分词 match关键字作用搜索条件是分词的
//}
//"terms":{
// "desc":["guank","is"] terms关键字作用可以多个关键词匹配
//}
//"match_phrase": {
// "desc": {
// "query": "guank is" match_phrase 关键字作用 先将查询条件进行分词 查询的结果必须包含查询条件 并且有顺序之分 guank 后面必须是 is 否则不会被查询出来
// "slop":3 slop 关键字的作用 在使用 match_phrase 下 词之间能跳过的词的数量 如 guank 和 is 之间存在3个其他词
// }
//"match":{
// "desc":{
// "query":"guank is",
// //"operator":"or" // operator 关键字 or: 或 and:guank 和 is 两者必须都满足
// "minimum_should_match":"60%" minimum_should_match 关键字 满足匹配度 60% 可以为整数 1 2 代表匹配其中的一个词语即可
// }
//}
//{
// "ids":{
// "type":"_doc",
// "values":["1001","1002","1003"] // 批量查询 Ids
// }
//}
},
"_source": [
"id",
"name",
"desc"
]
, "from": 0
, "size": 20
}
条件查询
POST my_doc/_search
{
"query": {
"multi_match": {
"query": "guank",
"fields": [
"desc" ,"nickname^10" // 多个字段匹配 desc 或 nickname 关键字 ^10 提升相应字段的权重
]
}
},
"_source": [
"id",
"name",
"desc"
]
}
bool查询
POST my_doc/_search
{
"query": {
"bool": {
"must": [ // must 关键字 must 中的多个条件都必须同时满足 should 关键字 should 中的条件是或关系 must_not 关键字条件中都不满足
{
"multi_match": {
"query": "guank",
"fields": [
"desc" ,"nickname"
]
}
}
]
}
},
"_source": [
"id",
"name",
"desc"
]
}
为查询的条件加权重
POST my_doc/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"desc": {
"query": "guank",
"boost": 1
}
}
},
{
"match": {
"name": {
"query": "guank"
}
}
}
]
}
},
"_source": [
"id",
"name",
"desc"
]
}
过滤器
POST my_doc/_search
{
"query": {
"match": {
"desc": "guank"
}
}
, "post_filter": {
"range": {
"id": {
"gte": 10,
"lte": 2000
}
}
}
}
排序
POST my_doc/_search
{
"query": {
"match": {
"desc": "guank"
}
}
,
"sort": [
{
"id": {
"order": "desc"
}
}
]
}
关键字高亮
POST my_doc/_search
{
"query": {
"match": {
"desc": "guank"
}
}
,
"sort": [
{
"id": {
"order": "desc"
}
}
],
"highlight": {
"pre_tags": ["<span>"], //自定义前缀标签
"post_tags": ["</span>"], //自定义后缀标签
"fields": {
"desc": {} // 高亮属性
}
}
}
ES 深度分页
在 es 中请求深度分页存在问题
POST my_doc/_search
{
"query": {
"match_all": {}
},
"_source": [
"id",
"name",
"desc"
]
, "from": 9999
, "size": 20
}
从 9999 向后搜索 20 会发生报错信息,这种情况会在数据太过多时出现分页数太多
返回的信息如下:
{
"error": {
"root_cause": [
{
"type": "illegal_argument_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [10019]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
],
"type": "search_phase_execution_exception",
"reason": "all shards failed",
"phase": "query",
"grouped": true,
"failed_shards": [
{
"shard": 0,
"index": "my_doc",
"node": "WzLANTsAS5Ke_04rsfTqMw",
"reason": {
"type": "illegal_argument_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [10019]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
}
],
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [10019]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting.",
"caused_by": {
"type": "illegal_argument_exception",
"reason": "Result window is too large, from + size must be less than or equal to: [10000] but was [10019]. See the scroll api for a more efficient way to request large data sets. This limit can be set by changing the [index.max_result_window] index level setting."
}
}
},
"status": 400
}
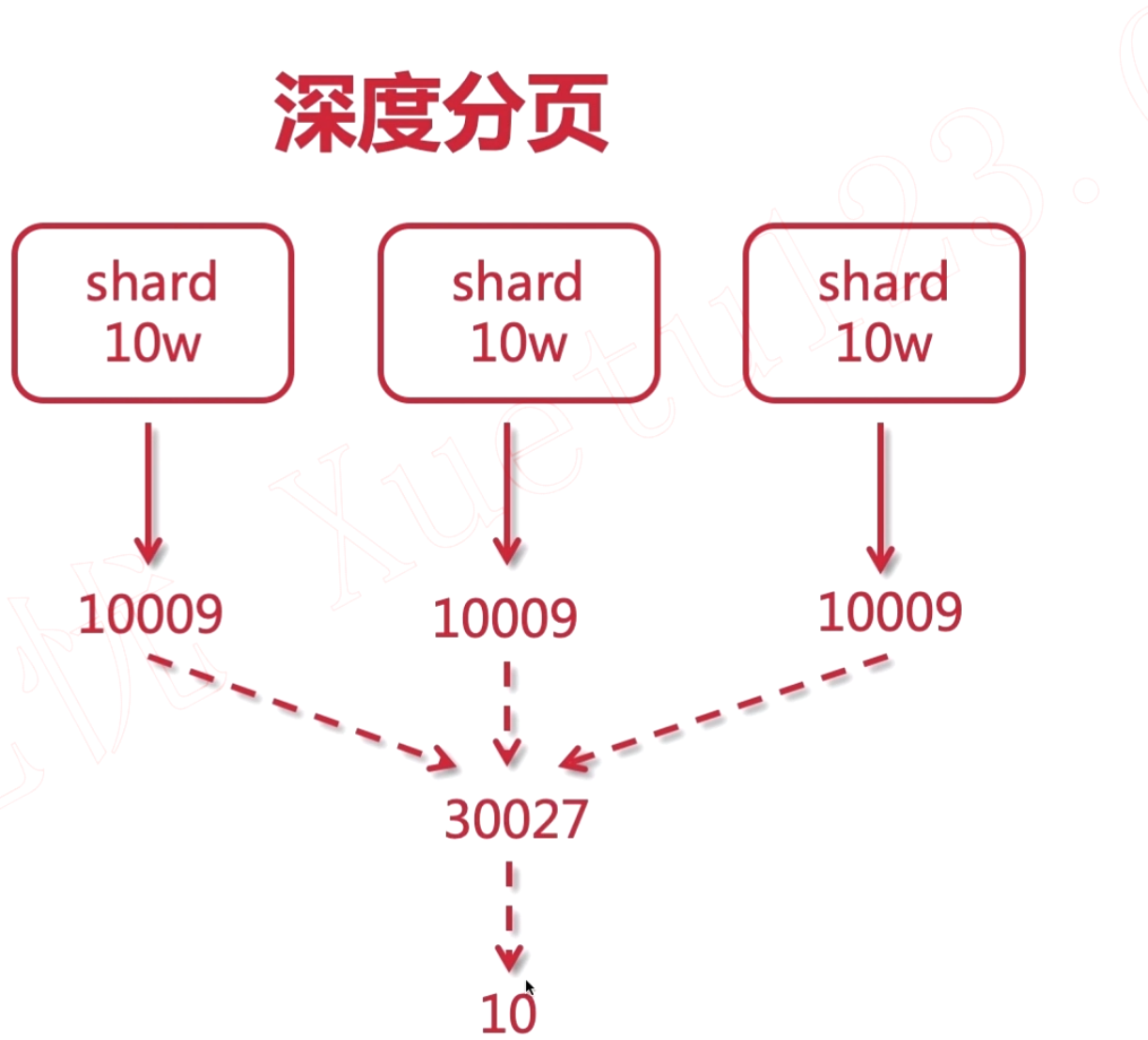
es 的分页查询机制:
在所有的 shard 中查询出 10009 条数据并且合并成 30027 条数据 然后进行排序 返回 10 条数据
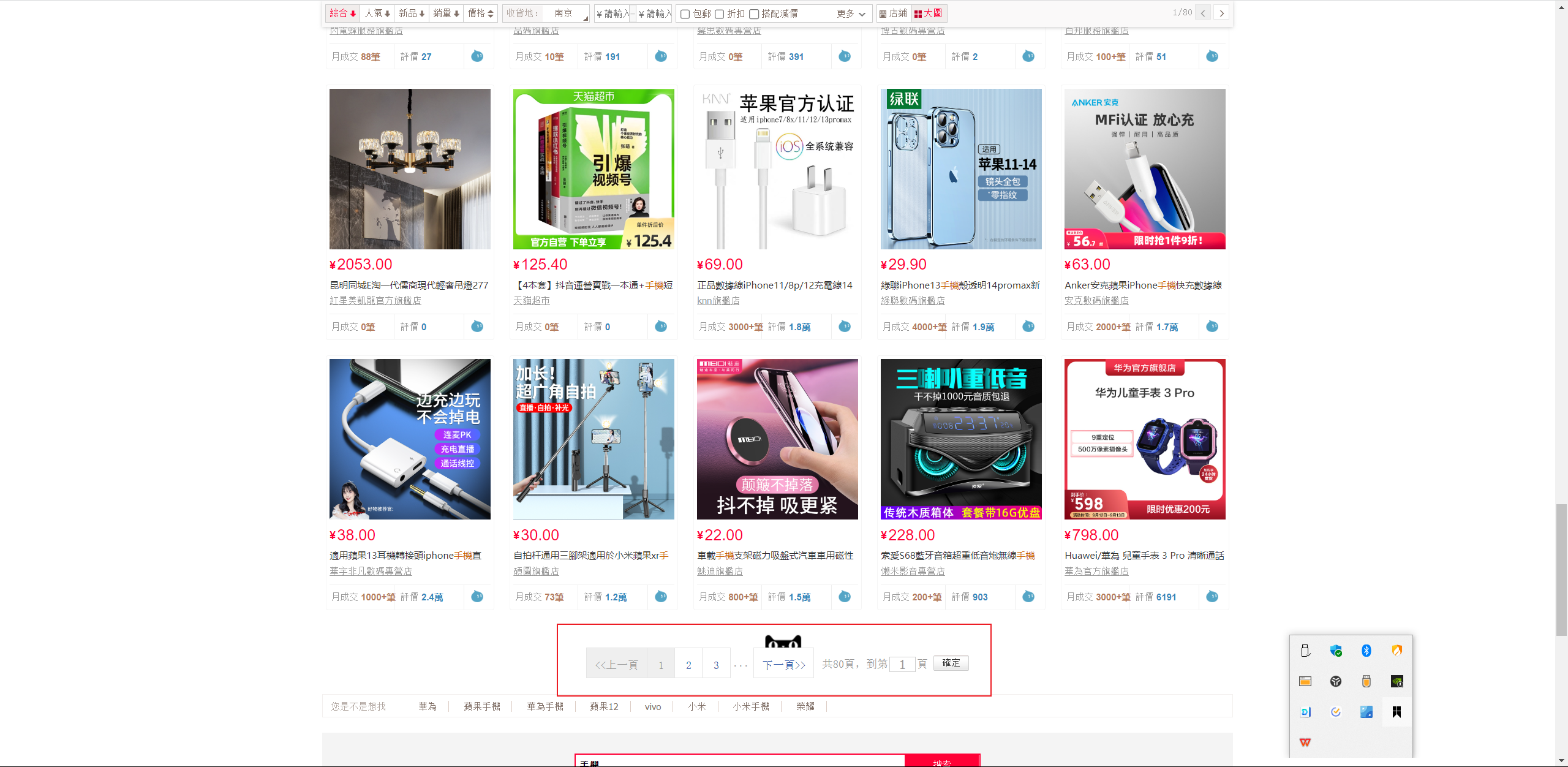
淘宝解决 es深度分页的措施 :每页查询结果60条 最大分页为 80页 用来限制记录数
scroll 滚动搜索
对于大数据量的查询 es 推荐使用 scroll api 进行滚动搜索
注意 : 使用
scroll进行搜索的时候 都是基于本次的快照数据
POST my_doc/_search?scroll=1m // scroll=1m 表示此次 scroll 搜索持续时间为 1 min
{
"query": {
"match_all": {}
},
"_source": [
"id",
"name",
"desc"
],
"sort": [
"_doc"
],
"size": 5
}
--------------------------------------------------
//返回数据
{
"_scroll_id" : "DXF1ZXJ5QW5kRmV0Y2gBAAAAAABW0_cWV3pMQU5Uc0FTNUtlXzA0cnNmVHFNdw==",
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : null,
"hits" : [
{
"_index" : "my_doc",
"_type" : "_doc",
"_id" : "1002",
"_score" : null,
"_source" : { },
"sort" : [
0
]
},
{
"_index" : "my_doc",
"_type" : "_doc",
"_id" : "2",
"_score" : null,
"_source" : { },
"sort" : [
1
]
},
{
"_index" : "my_doc",
"_type" : "_doc",
"_id" : "1",
"_score" : null,
"_source" : {
"name" : "guank",
"id" : 1001,
"desc" : "guank is very good"
},
"sort" : [
2
]
}
]
}
}
// 使用 scroll_id 和 scroll 继续进行本次搜索
POST _search/scroll
{
"scroll_id" :"DXF1ZXJ5QW5kRmV0Y2gBAAAAAABW2ewWV3pMQU5Uc0FTNUtlXzA0cnNmVHFNdw==",
"scroll":"3m"
}
批量查询
POST /my_doc/_mget
{
"ids":["1002","1","2"]
}
批量操作 bulk
bulk操作和以往的普通请求格式有区别。不要格式化 json ,不然不在同一行了
{action: {metadata}}\n
{request body}\n
{action: {metadata}}\n
{request body}\n
{action: {metadata}}代表批量操作的类型,可以是新增、删除或修改\n是每行结尾必须填写的一个规范,每行包括最后一行都要填写,用于 es 的解析{request body}是请求 Body,增加和修改操作需要,删除操作则不需要
POST /_bulk
{"create":{"_index":"shop2","_type":"_doc","_id":"2001"}}
{"id":"2001","nickname":"guank-2001"}
{"create":{"_index":"shop2","_type":"_doc","_id":"2002"}}
{"id":"2002","nickname":"guank-2002"}
{"create":{"_index":"shop2","_type":"_doc","_id":"2003"}}
{"id":"2003","nickname":"guank-2003"}
注意最后必须用回车结尾
-
create 创建已有id文档在 url 中指定 index 和 type
POST my_doc/_bulk {"create":{"_id":"2003"}} {"id":"2003","nickname":"name2003"} -
index 创建文档 已有文档会被覆盖 没有则会新增
POST my_doc/_bulk {"index":{"_id":"2004"}} {"id":"2004","nickname":"name2004"} -
update 更新
POST my_doc/_bulk {"update":{"_id":"2004"}} {"doc":{"id":"3004"}} -
批量删除
POST my_doc/_bulk {"delete":{"_id":"2004"}}
bulk 批量请求的性能限制
整个批量请求都需要由接收到请求的节点加载到内存中,因此该请求越大,其他请求所能获得的内存就越少。 批量请求的大小有一个最佳值,大于这个值,性能将不再提升,甚至会下降。 但是最佳值不是一个固定的值。它完全取决于硬件、文档的大小和复杂度、索引和搜索的负载的整体情况。
幸运的是,很容易找到这个 最佳点 :通过批量索引典型文档,并不断增加批量大小进行尝试。 当性能开始下降,那么你的批量大小就太大了。一个好的办法是开始时将 1,000 到 5,000 个文档作为一个批次, 如果你的文档非常大,那么就减少批量的文档个数。
密切关注你的批量请求的物理大小往往非常有用,一千个 1KB 的文档是完全不同于一千个 1MB 文档所占的物理大小。 一个好的批量大小在开始处理后所占用的物理大小约为 5-15 MB。
Elasticsearch 集群
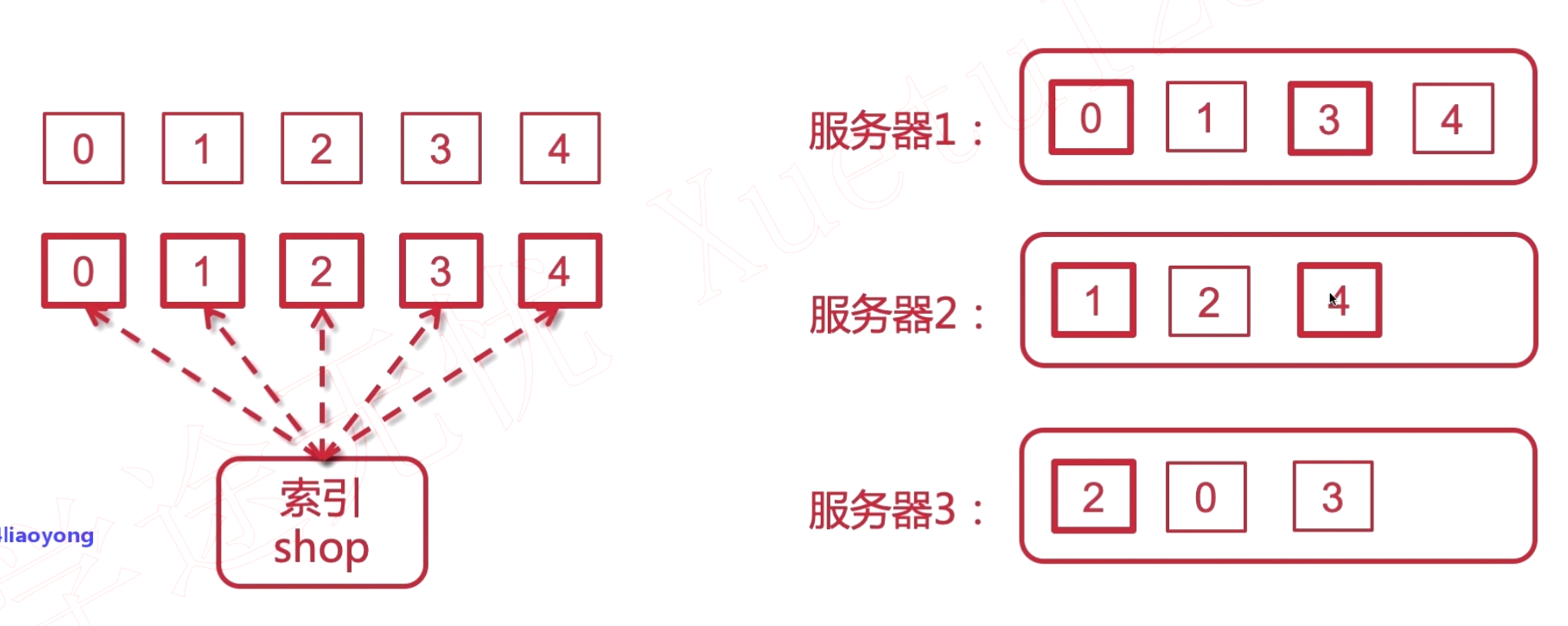
同一分片的主分片和副分片不能处在同一个服务器上
配置文件
node.master: true // 在节点的配置文件里设置为 true 代表该节点有被选举为 master 节点的资格
node.data: true // 数据节点
discovery.seed_hosts: ["所有节点的 ip 地址","",""]
// 配置文件完成启动 es
Elasticsearch 集群分片
在 Elasticsearch 集群中 一主两从模式 从节点宕机后 该从节点的数据分片丢失 原本在主节点和另一从节点的数据分片会重新分配 ,在该宕机的从节点恢复之后重新加入集群,该从节点的数据分片则全是副本分片。
在主节点宕机的情况下,两个从节点经过选举出一个作为主节点,当宕机的主节点恢复后加入集群后,这个主节点会作为一个从节点而非重新成为主节点
Elasticsearch 集群脑裂问题
所谓脑裂问题(类似于精神分裂),就是同一个集群中的不同节点,对于集群的状态有了不一样的理解。将请求发向不同的节点之后,我却发现即使是总体状态是red的,但是可用的节点数量却不一致。
正常情况下,集群中的所有的节点,应该对集群中master的选择是一致的,这样获得的状态信息也应该是一致的,不一致的状态信息,说明不同的节点对master节点的选择出现了异常——也就是所谓的脑裂问题。这样的脑裂状态直接让节点失去了集群的正确状态,导致集群不能正常工作。
可能导致的原因:
1.网络原因:
由于是内网通信,网络通信问题造成某些节点认为master死掉,而另选master的可能性较小;进而检查Ganglia集群监控,也没有发现异常的内网流量,故此原因可以排除。
2. 节点负载:
由于master节点与data节点都是混合在一起的,所以当工作节点的负载较大(确实也较大)时,导致对应的ES实例停止响应,而这台服务器如果正充当着master节点的身份,那么一部分节点就会认为这个master节点失效了,故重新选举新的节点,这时就出现了脑裂;同时由于data节点上ES进程占用的内存较大,较大规模的内存回收操作也能造成ES进程失去响应。所以,这个原因的可能性应该是最大的。
应对问题的办法:
方法1:
对应于上面的分析,推测出原因应该是由于节点负载导致了master进程停止响应,继而导致了部分节点对于master的选择出现了分歧。为此,一个直观的解决方案便是将master节点与data节点分离。为此,我们添加了三台服务器进入ES集群,不过它们的角色只是master节点,不担任存储和搜索的角色,故它们是相对轻量级的进程。可以通过以下配置来限制其角色:
node.master: true
node.data: false
当然,其它的节点就不能再担任master了,把上面的配置反过来即可。这样就做到了将master节点与data节点分离。当然,为了使新加入的节点快速确定master位置,可以将data节点的默认的master发现方式有multicast修改为unicast:
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: ["master1", "master2", "master3"]
还有两个直观的参数可以减缓脑裂问题的出现:
discovery.zen.ping_timeout(默认值是3秒):默认情况下,一个节点会认为,如果master节点在3秒之内没有应答,那么这个节点就是死掉了,而增加这个值,会增加节点等待响应的时间,从一定程度上会减少误判。
discovery.zen.minimum_master_nodes(默认是1):这个参数控制的是,一个节点需要看到的具有master节点资格的最小数量,然后才能在集群中做操作。官方的推荐值是(N/2)+1,其中N是具有master资格的节点的数量(我们的情况是3,因此这个参数设置为2,但对于只有2个节点的情况,设置为2就有些问题了,一个节点DOWN掉后,你肯定连不上2台服务器了,这点需要注意)。
其中,参数 discovery.zen.minimum_master_nodes 在 Elasticsearch 版本 7.x 中被舍弃,这部分配置由 Elasticsearch 自己去实现和使用。
Elasticsearch 集群的文档读写原理
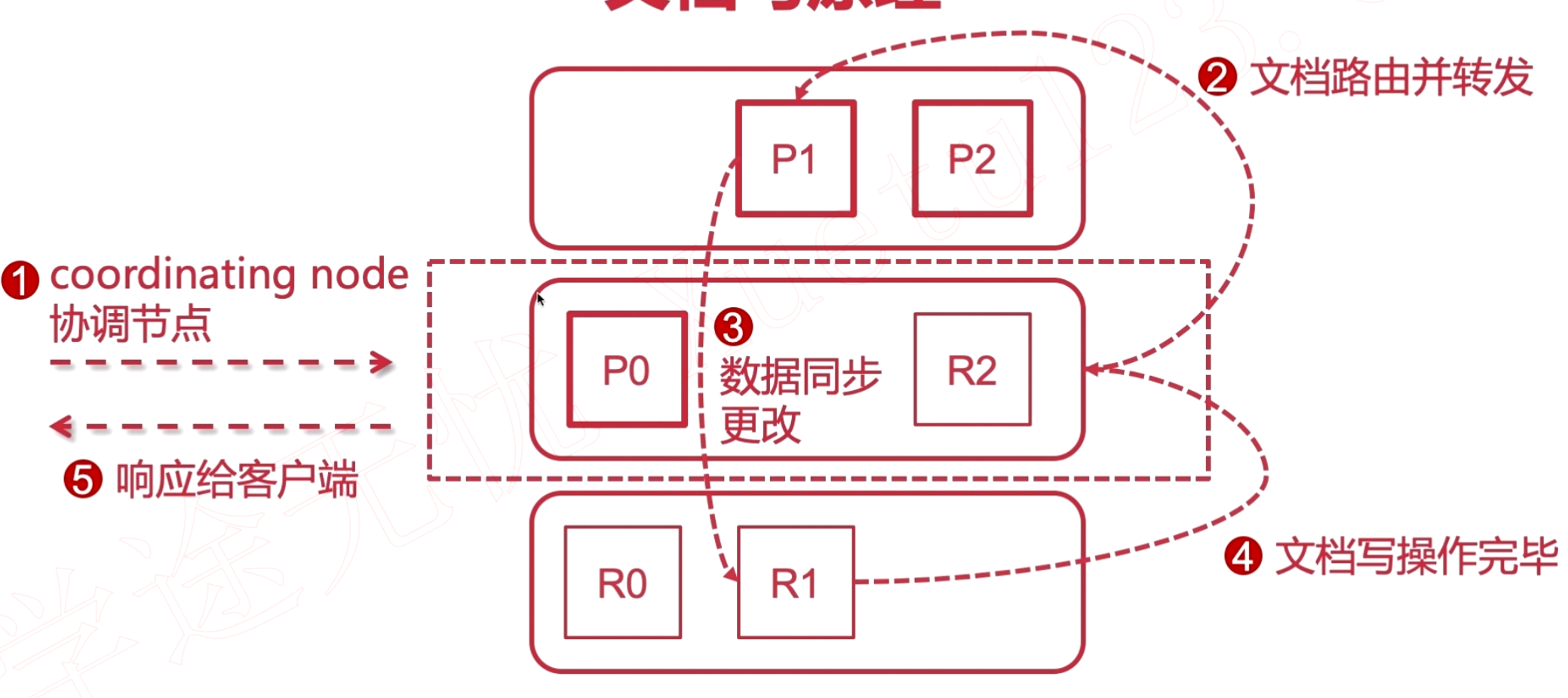
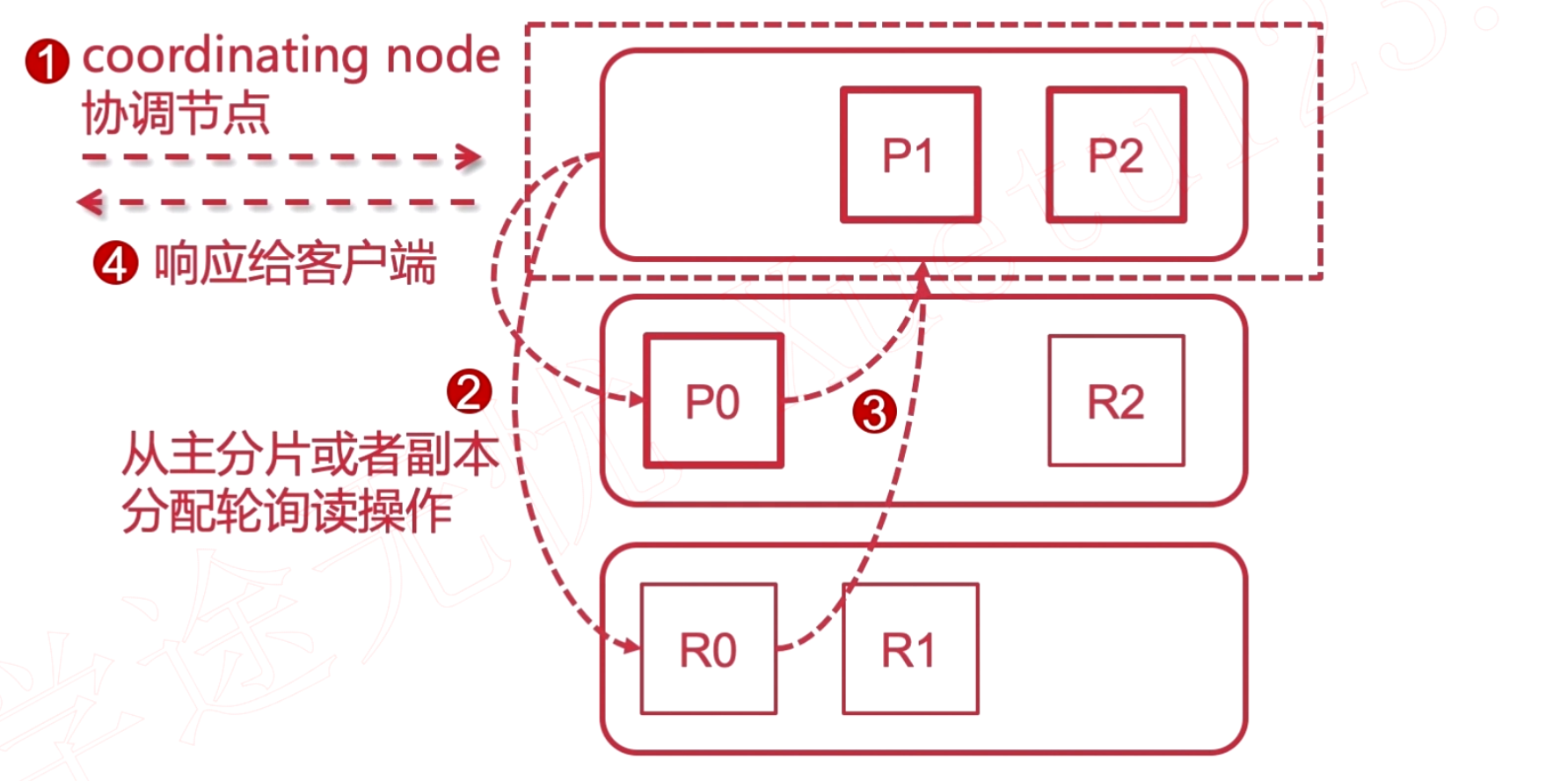
通过 elasticsearchRestTemplate 和 ElasticsearchRepository 使用Springboot 操作 Elasticsearch
@Data
@AllArgsConstructor
@NoArgsConstructor
@Document(indexName = "student", shards = 5, replicas = 1)
public class Student {
@Id
private String id;
@Field(store = true, type = FieldType.Text, analyzer = "ik_max_word", searchAnalyzer = "ik_smart")
private String name;
}
----------------------------------------------------------------------------------------------------------
@Repository
public interface StudentESDao extends ElasticsearchRepository<Student,String> {
}
----------------------------------------------------------------------------------------------------------
@RunWith(SpringRunner.class)
@SpringBootTest(classes = Application.class)
@Slf4j
public class ESTest {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Autowired
private StudentESDao studentESDao;
@Test
public void createIndex() {
Student student = new Student();
studentESDao.index(student);
elasticsearchRestTemplate.createIndex(Student.class, student);
}
@Test
public void deleteIndex() {
elasticsearchRestTemplate.deleteIndex(Student.class);
}
@Test
public void updateDoc() {
Student student = new Student();
student.setId("1002");
UpdateRequest request = new UpdateRequest();
request.index("student").id(student.getId());
request.doc(JSON.toJSONString(student), XContentType.JSON);
UpdateQuery query = new UpdateQueryBuilder().withClass(Student.class)
.withId(student.getId())
.withUpdateRequest(request)
.build();
elasticsearchRestTemplate.update(query);
}
@Test
public void query() {
Student student = new Student();
student.setId("1002");
Optional<Student> byId =
studentESDao.findById(student.getId());
GetQuery query = new GetQuery();
query.setId(student.getId());
Student student1 = elasticsearchRestTemplate.queryForObject(query, Student.class);
byId.ifPresent(o -> log.info(JSON.toJSONString(o)));
}
@Test
public void delete() {
Student student = new Student();
student.setId("1002");
studentESDao.delete(student);
elasticsearchRestTemplate.delete(Student.class, student.getId());
}
@Test
public void search() {
QueryBuilder queryBuilder = QueryBuilders.matchQuery("id","1001");
//查询全部数据
// QueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
// 精确查询 =
// QueryBuilder queryBuilder = QueryBuilders.termQuery("name", "lisi");
// 精确查询 多个 in
// QueryBuilder queryBuilder = QueryBuilders.termsQuery("name", "张三", "lisi");
// match匹配,会把查询条件进行分词,然后进行查询,多个词条之间是 or 的关系,可以指定分词
// QueryBuilder queryBuilder = QueryBuilders.matchQuery("name", "张三");
// QueryBuilder queryBuilder = QueryBuilders.matchQuery("name", "张三").analyzer("ik_max_word");
// match匹配 查询多个字段
// QueryBuilder queryBuilder = QueryBuilders.multiMatchQuery("男", "name", "sex");
// fuzzy 模糊查询,返回包含与搜索字词相似的字词的文档。
// QueryBuilder queryBuilder = QueryBuilders.fuzzyQuery("name","lisx");
// prefix 前缀检索
// QueryBuilder queryBuilder = QueryBuilders.prefixQuery("name","张");
// wildcard 通配符检索
// QueryBuilder queryBuilder = QueryBuilders.wildcardQuery("name","张*");
// regexp 正则查询
// QueryBuilder queryBuilder = QueryBuilders.regexpQuery("name", "(张三)|(lisi)");
// boost 评分权重,令满足某个条件的文档的得分更高,从而使得其排名更靠前。
// queryBuilder.boost(2);
// 多条件构建
// BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
// 并且 and
// queryBuilder.must(QueryBuilders.termQuery("name", "张三"));
// queryBuilder.must(QueryBuilders.termQuery("sex", "女"));
// 或者 or
// queryBuilder.should(QueryBuilders.termQuery("name", "张三"));
// queryBuilder.should(QueryBuilders.termQuery("name", "lisi"));
// 不等于,去除
// queryBuilder.mustNot(QueryBuilders.termQuery("name", "lisi"));
// 过滤数据
// queryBuilder.filter(QueryBuilders.matchQuery("name", "张三"));
// 范围查询
/*
gt 大于 >
gte 大于等于 >=
lt 小于 <
lte 小于等于 <=
*/
// queryBuilder.filter(new RangeQueryBuilder("age").gt(10).lte(50));
// 构建分页,page 从0开始
Pageable pageable = PageRequest.of(0, 3);
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.withPageable(pageable)
//排序
.withSort(SortBuilders.fieldSort("_score").order(SortOrder.DESC))
//投影
.withFields("name")
.build();
Page<Student> search = studentESDao.search(searchQuery);
}
@Test
public void highLight() {
String preTag = "<font color='red'>";
String postTag = "</font>";
QueryBuilder queryBuilder = QueryBuilders.matchQuery("id","1001");
HighlightBuilder.Field field = new HighlightBuilder.Field("name").preTags(preTag).postTags(postTag);
SearchQuery searchQuery = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.withHighlightFields(field)
//排序
.withSort(SortBuilders.fieldSort("_score").order(SortOrder.DESC))
//投影
.withFields("name")
.build();
SearchResultMapper searchResultMapper = new SearchResultMapper() {
@Override
public <T> AggregatedPage<T> mapResults(SearchResponse response, Class<T> clazz, Pageable pageable) {
List<Student> list = new ArrayList<>();
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
HighlightField highlightField = hit.getHighlightFields().get("name");
String name = Optional.ofNullable(highlightField.getFragments())
.map(texts -> Arrays.stream(texts).map(Text::toString)
.collect(Collectors.toList()))
.orElse(Collections.emptyList()).stream().findFirst().orElse("");
Student stuHL = new Student();
stuHL.setName(name);
String id = (String) hit.getSourceAsMap().get("id");
stuHL.setId(id);
list.add(stuHL);
}
if (!CollectionUtils.isEmpty(list)) {
return new AggregatedPageImpl<>((List<T>) list);
}
return null;
}
@Override
public <T> T mapSearchHit(SearchHit searchHit, Class<T> type) {
return null;
}
};
AggregatedPage<Student> list = elasticsearchRestTemplate.queryForPage(searchQuery, Student.class, searchResultMapper);
}
}
Logstash 数据同步
- 数据采集
- 以 id 或 update_time 作为同步边界
- logstash-input-jdbc 插件
-
自定义分词模板
logstash-ik.json{ "order": 0, "version": 1, "index_patterns": ["*"], "settings": { "index": { "refresh_interval": "5s" } }, "mappings": { "_default_": { "dynamic_templates": [ { "message_field": { "path_match": "message", "match_mapping_type": "string", "mapping": { "type": "text", "norms": false } } }, { "string_fields": { "match": "*", "match_mapping_type": "string", "mapping": { "type": "text", "norms": false, "analyzer": "ik_max_word", "fields": { "keyword": { "type": "keyword", "ignore_above": 256 } } } } } ], "properties": { "@timestamp": { "type": "date" }, "@version": { "type": "keyword" }, "geoip": { "dynamic": true, "properties": { "ip": { "type": "ip" }, "location": { "type": "geo_point" }, "latitude": { "type": "half_float" }, "longitude": { "type": "half_float" } } } } } }, "aliases": {} } -
配置 Logstash
logstash-db-sync.confinput { jdbc { # 设置 MySql/MariaDB 数据库url以及数据库名称 jdbc_connection_string => "jdbc:mysql://192.168.1.6:3306/foodie-shop-dev?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true" # 用户名和密码 jdbc_user => "root" jdbc_password => "root" # 数据库驱动所在位置,可以是绝对路径或者相对路径 jdbc_driver_library => "/usr/local/logstash-6.4.3/sync/mysql-connector-java-5.1.41.jar" # 驱动类名 jdbc_driver_class => "com.mysql.jdbc.Driver" # 开启分页 jdbc_paging_enabled => "true" # 分页每页数量,可以自定义 jdbc_page_size => "1000" # 执行的sql文件路径 statement_filepath => "/usr/local/logstash-6.4.3/sync/foodie-items.sql" # 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务 schedule => "* * * * *" # 索引类型 type => "_doc" # 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件 use_column_value => true # 记录上一次追踪的结果值 last_run_metadata_path => "/usr/local/logstash-6.4.3/sync/track_time" # 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间 tracking_column => "updated_time" # tracking_column 对应字段的类型 tracking_column_type => "timestamp" # 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录 clean_run => false # 数据库字段名称大写转小写 lowercase_column_names => false } } output { elasticsearch { # es地址 hosts => ["192.168.1.187:9200"] # 同步的索引名 index => "foodie-items" # 设置_docID和数据相同 document_id => "%{id}" # document_id => "%{itemId}" # 定义模板名称 template_name => "myik" # 模板所在位置 template => "/usr/local/logstash/sync/logstash-ik.json" # 重写模板 template_overwirte => true # 默认为 true, false 关闭 logstash 自动管理模板功能,如果自定义模板,则设置为 false manage_template => false } # 日志输出 stdout { codec => json_lines } } -
启动Logstash
cd logstash/bin ./logstash -f /usr/local/logstash-6.4.3/sync/logstash-db-sync.conf
评论区