



分布式日志追踪
SpringCloud Sleuth + Zipkin 概览
一次请求从开始到返回必然会经过至少两个微服务模块,而这些微服务模块都是独立部署的,都拥有自己的JVM,对于定位问题来说非常麻烦。因此对一次请求的完整的链路追踪是有必要的。
认识SpringCloud Sleuth
-
SpringCloud Sleuth实现的功能是,它会自动为当前的应用构建起各通信信道的跟踪机制
-
通过如
RabbitMQ、Kafka(或者其他任何SpringCloud Stream绑定器实现的消息中间件)传递的请求。 -
通过
Zuul、Gateway代理传递的请求。 -
通过
RestTemplate发起的请求。
-
SpringCloud Sleuth跟踪实现原理
-
为了实现请求跟踪:当请求发送到分布式系统的入口端点时,只需要服务跟踪框架为该请求创建一个唯一的跟踪标识,
Trace ID -
为了统计各处理单元的时间延迟,当请求到达各个服务组件时,或是处理逻辑到达某个状态时,也通过一个唯一标识来标记它的开始、具体过程以及结束,Span ID。

认识 Zipkin
Zipkin的基础概念
-
Zipkin解决微服务架构中的延迟问题,包括数据的收集、储存、查找和展现
-
Zipkin有四大核心组件构成:
-
Collector:收集器组件 -
Storage:储存组件 -
API:Restful API,提供外部访问接口 -
UI:Web UI,提供可视化查询页面
-
集成SpringCloud Sleuth实现微服务通信跟踪
集成SpringCloud Sleuth的步骤
- 第一原则:保证你的微服务存在跨进程通信。
- 在
pom.xml中添加依赖配置
搭建Zipkin Server实现对跟踪信息的收集
搭建Zipkin Server的步骤
curl -sSL https://zipkin.io/quickstart.sh | bash -s
java -jar zipkin.jar
或者使用docker
docker run -d -p 9411:9411 openzipkin/zipkin
访问ip:9411


配置Zipkin Server实现对跟踪日志的收集
-
为什么需要对Zipkin Server做自定义配置
- 默认情况下,Zipkin Server将跟踪信息储存在内存中(JVM),重启会丢失
- Zipkin Server默认使用的时HTTP方式上报跟踪数据,性能较差
-
Zipkin Server配置MySQL跟踪数据持久化
-
Mysql中添加数据表:

-
java -jar zipkin.jar --STORAGE_TYPE=mysql --MYSQL_HOST=127.0.0.1 --MYSQL_TCP_PORT=3306 --MYSQL_USER=root --MYSQL_PASS=123456 --MYSQL_DB=imooc_zipkin Docker命令 docker run --name zipkin_mysql -d -p 9411:9411 -e STORAGE_TYPE=mysql -e MYSQL_HOST=192.168.0.103 -e MYSQL_TCP_PORT=3306 -e MYSQL_USER=root -e MYSQL_PASS=123456 -e MYSQL_DB=imooc_zipkin openzipkin/zipkin:2.21.7
-
Spring cloud Sleuth 整合Zipkin实现分布式链路跟踪,收集
步骤
-
pom文件中添加依赖
<!-- zipkin = spring-cloud-starter-sleuth + spring-cloud-sleuth-zipkin--> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> -
在工程的bootstrap中增加Zipkin的配置
我们不选择Zipkin默认的
http方式进行数据的传输,而是使用Kafka来对数据进行传输 -
下载、安装Kafka配置跟踪数据传输
使用docker
docker run --name zipkin #名称 -p 9411:9411 #暴露端口 -e "STORAGE_TYPE=mysql" -e "MYSQL_HOST=192.168.0.103" #es地址 -e "MYSQL_TCP_PORT=3306" -e "MYSQL_USER=root" -e "MYSQL_PASS=123456" -e MYSQL_DB=imooczipkin -e "COLLECTOR_KAFKA_ENABLED=true" #以kafka方式传输 -e "KAFKA_BOOTSTRAP_SERVERS=10.0.1.104:9092,10.0.1.117:9092,10.0.1.127:9092" #kafka地址 -e "KAFKA_GROUP_ID=zipkin" #组 -e "KAFKA_TOPIC=zipkin" #主题 -e "KAFKA_STREAMS=1" #线程数 -idt openzipkin/zipkin #镜像名SpringCloud Sleuth 设置采样率、抽样收集策略
可以自由选择Zipkin brave自带的两个抽样策略
-
ProbabilityBaseSampler采样率策略
- 默认使用的策略,以请求百分比的方式配置和收集跟踪信息:它的默认值为0.1,代表收集10%的请求跟踪信息
- spring.sleuth.sample.probability=0.5
-
RateLimitingSampler 抽样策略
- 限速采集,也就是说它可以用来限制每秒追踪请求的最大数量,优先级更高(相对于采样率策略)
- spring.sleuth.sampler.rate=10
-
可以在
bootstrap.yml中配置或者在代码中编写配置类sleuth: sampler: # ProbabilityBasedSampler 抽样策略 probability: 1.0 # 采样比例, 1.0 表示 100%, 默认是 0.1 # RateLimitingSampler 抽样策略, 设置了限速采集, spring.sleuth.sampler.probability 属性值无效 rate: 100 # 每秒间隔接受的 trace 量 -
采用在代码中方编写的方式
/** * @author qingtian * @version 1.0 * @description: 使用配置的方式设置抽样率 * @date 2022/1/1 20:53- */ @Configuration public class SamplerConfig { /** * @description: 限速采集 * @param: * @return: brave.sampler.Sampler * @date: 2022/1/1 20:55 */ @Bean public Sampler sampler() { return RateLimitingSampler.create(100); } // /** // * @description: 概率采集,这两个中间使用一个就行,一般使用限速采集 // * @param: // * @return: brave.sampler.Sampler // * @date: 2022/1/1 20:56 // */ // @Bean // public Sampler defaultSampler() { // return ProbabilityBasedSampler.create(0.5f); // } }
Brave解读
Brave中常用的数据结构及其说明
- Tracing :工具类,用于Tracer类实例
- Tracer:也是工具类,用于生成Span
- Span:实际记录每个功能块执行信息的类
- TraceContext:记录Trace的执行过程中的元数据信息
- Propagation:用于在分布式环境或者跨进程条件下的trace跟踪时实现TraceContext传递的工具类
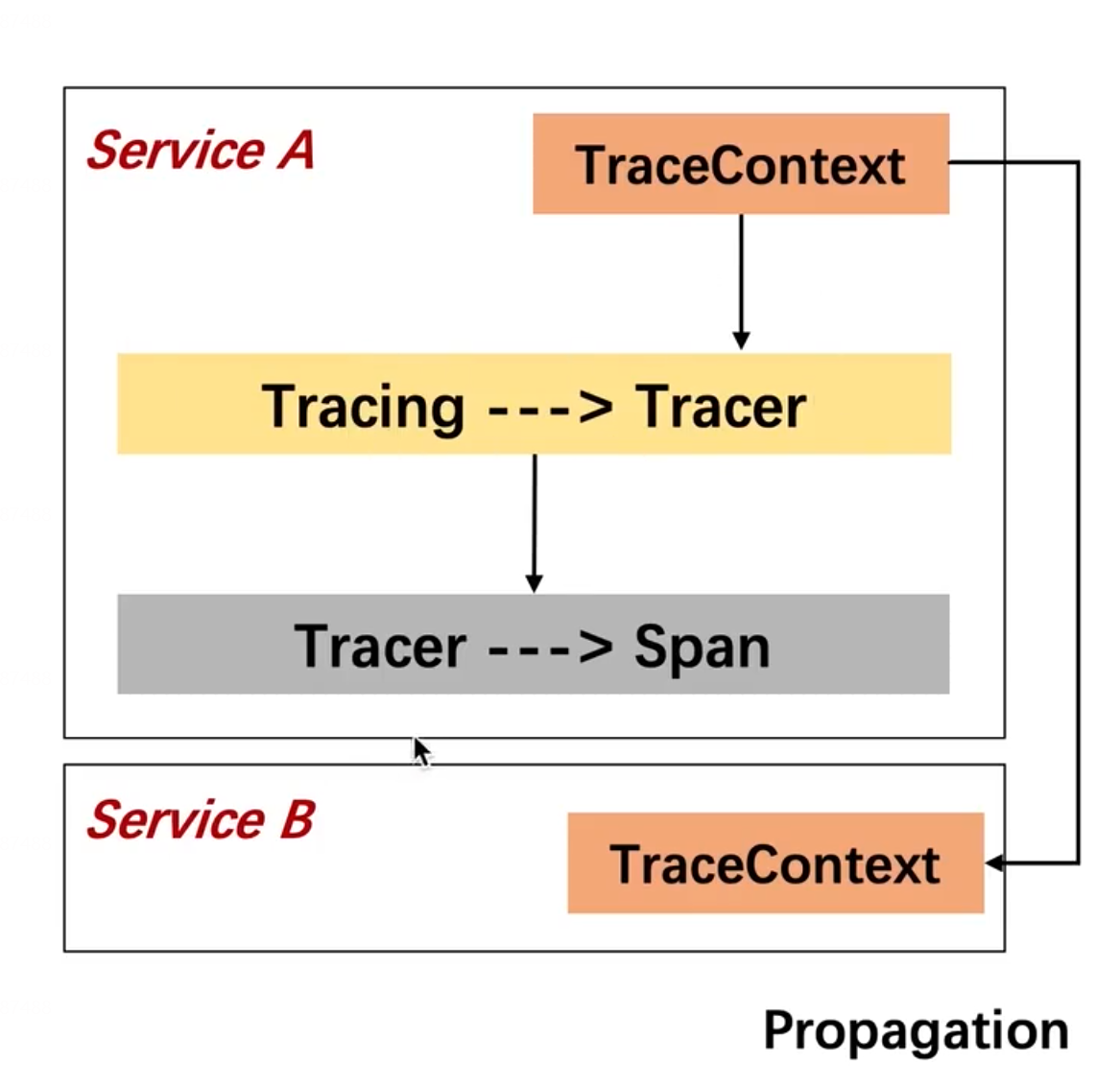
SpringCloud ZSleuth如何实现跨服务Trace追踪
SpringCloud Sleuth 实现跨服务Trace追踪
-
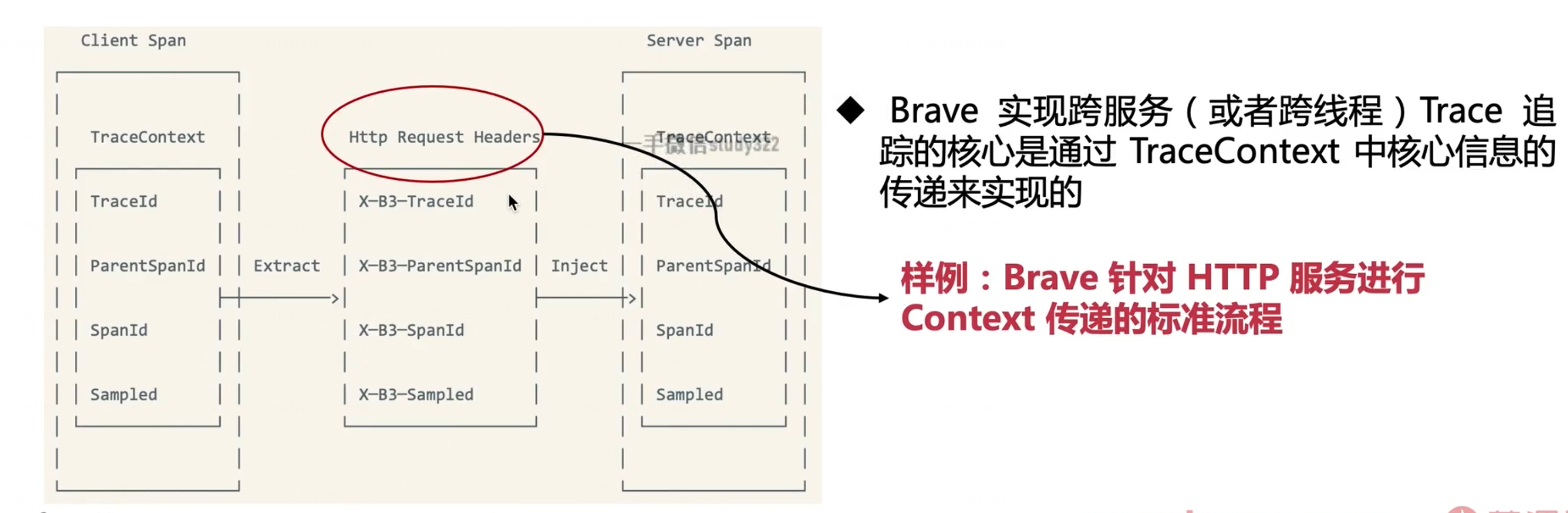
SpringCloud Sleuth和Brave提供了很多不同的分布式框架的支持,例如gRPC、Kafka、HTTP等
评论区